


Explore software’s major benefits
Check out the major benefits of the PDF Extractor tool, which can securely extract the different elements of a PDF file without any hassle.
Custom extraction
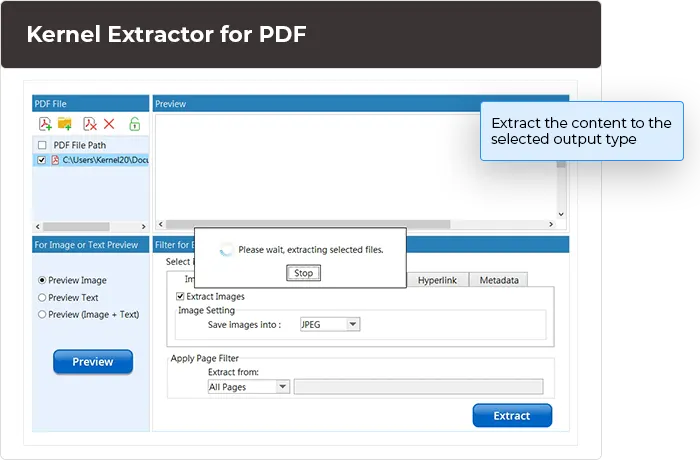
Using the Kernel Extractor for PDF, you can extract all content collectively or select what you need to extract out of available data such as images, text, bookmarks, comments, etc. The PDF extractor tool allows easy customization of the process with the “Select item type and apply filter”.
Extract items securely
PDF word extractor does not modify or manipulate the data after extracting it from the file. All the page hierarchy and structure of the content are preserved, and each data item is saved in separate folders and labeled according to the data type.
Image quality not affected
Performing extraction of images using PDF image extractor has no impact on the quality of the images added in the source PDFs. Simply choose the format you want to extract all images from the selected PDF and press the extract button.
Compatible to all Windows
Extract PDF file on any version of Windows. Our tool is compatible with all Windows versions, including Windows 365 (Cloud PC)/ 11/ 10/ 8 /7 Service Pack 1, Windows Server 2022/ 2019/ 2016/ 2012 R2/ 2012/ 2008/ 2003.
