

Read time: 5 minutes
Portable File Document is not as great a program as Microsoft Word when it comes to reading and extracting text from it. One can easily save the text from a Word file, but from a PDF file, it is a bit tricky. Most of the PDF readers only let you view the data but can’t extract text from PDFs. This problem becomes even more complicated if your document has graphs, tables, or some other form of non-linear data.
The need to extract text from PDF may develop due to various reasons such as text analysis, use of the text in another document, translation of the text, and many more. Some users may extract text from PDF to Word to update or restructure the content. This article will show you how to extract text from PDF file with native methods as well as with a professional tool.
Top Solutions to Extract Text from PDF
You have a variety of options to extract text from PDF files, depending on your needs. You can choose the most convenient solution below.
Method 1. Using Adobe Acrobat Reader
Acrobat Reader allows you to copy and paste text from PDF files. With Adobe Acrobat Reader, you just need to copy the part of the PDF file you need and then paste it into another program. You can easily copy the portion of the text by holding the mouse left click and then using Ctrl + C to copy that part of the file.
Now, you need to paste that copied content into word processing programs, such as Microsoft Word.
1. Save complete PDF as text
With Acrobat Reader, you can’t just export selective text; instead, you can save the complete PDF file as text with no other elements. To do so follow the steps below:
- Open the PDF file in Acrobat Reader.
- Click File and select the option Save as Text.
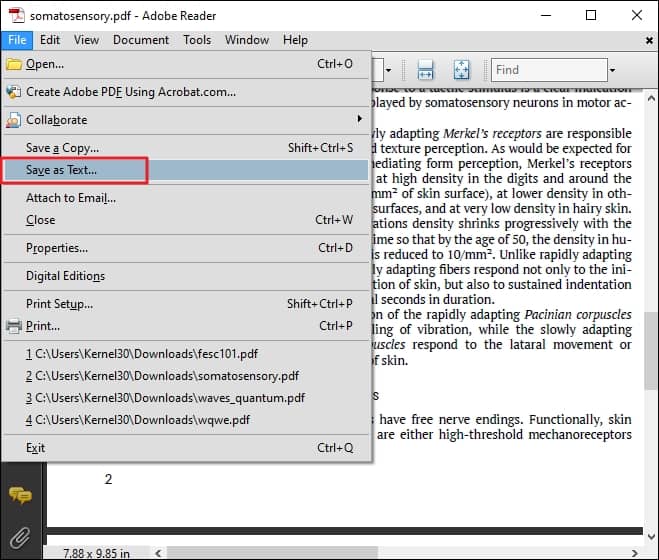
- Provide the destination to save the text file and click Save.
- The text version of the entire PDF will be extracted and saved.
Method 2. Using Free online PDF to Text Tools
Another way to extract text from PDF is to use the free online website. Many websites offer different operations related to PDFs, split, convert & extract text out of PDF file. However, these websites require users to upload PDF files online. Therefore, security is always in question. Finding a reliable website to extract text from PDF without compromising confidential data is challenging. Therefore, we recommend being careful with what data you are uploading for text extraction. To avoid privacy concerns, it’s better to use offline software.
Also, for an interruption-free PDF to text conversion, make sure there is no underlying PDF error in the file. Errors like “Blank PDF file,” “unable to open PDF,” and more must be treated before uploading the files for conversion. The presence of any error can quickly halt the extraction process, which will ultimately lead to a waste of time.
Extracting Text with Best PDF Extractor Tool
The above two methods we discussed can easily extract text from PDF. However, one major drawback they have is that they cannot preserve the original layout of the text document during extraction. To extract all text from PDF file while preserving the original format and layout, you must use a professional tool.
Kernel Extractor for PDF is an advanced tool embedded with powerful algorithms. The PDF extractor tool deeply scans the PDF file and carefully extract text out of PDF while ensuring original file structure.
Some prominent features of PDF tool:
- Extract text from selective pages with smart filters.
- Ability to extract all text from PDF effortlessly.
- Extract Images from PDF in multiple formats such as JPEG, TIFF, GIF, PNG, and BMP.
- Extract metadata, hyperlinks, comments, and bookmarks from PDF file.
- Ensure complete data integrity during extraction.
- Extract text from secured PDF file.
Closing Notes
We started with a puzzling question, ‘How to extract text from PDF document?’ and now we have all the answers to it. Use the above-discussed methods to extract text from PDF document quickly. To ensure the original formatting of text we recommend employing Kernel Extractor for PDF tool. Along with text you can also extract pages from single or multiple PDF files.
Frequentlty Asked Questions
A.You can use Acrobat Reader or any free online tool to extract text from single PDF file. However, for the extraction of text from multiple PDFs, you will need assistance from Kernel PDF extractor tool.
A. To extract text from scanned PDF, you will need a tool with Optical Character Recognition feature (OCR). OCR can scan and generate text out of digital images. Free OCR tools exist for image-to-text conversion. However, their accuracy is not satisfactory. For the best result you must try a professional paid tool.
A. To extract Hindi text from PDF, you will need an OCR tool that supports Hindi language fonts. Free online tools do exist, but they have security and accuracy concerns.
A. Yes, Kernel Extractor for PDF can extract text from protected PDF files easily. Apart from text, the tool is capable of exporting images, hyperlinks, metadata, and bookmarks from PDFs.
A. You will need an advanced tool embedded with Optical Character Recognition (OCR) facility to extract text from a PDF image. The OCR will scan the photo and determine the font language to generate the text present on the image.
A. Open Bluebeam PDF in any browser or PDF reader tool. Select the text you want and copy it. Then, paste the copied text into any text editor. Alternatively, you can try Kernel PDF extractor tool to quickly extract text from any PDF file along with other PDF elements like images, metadata, etc.






